
Multithreading and Memory-Mapping: Refining ANN Performance with Arroy
Note
This is one blog post in a series:
- Spotify-Inspired: Elevating Meilisearch with Hybrid Search and Rust,
- Multithreading and Memory-Mapping: Refining ANN Performance with Arroy,
- Meilisearch Expands Search Power with Arroy's Filtered Disk ANN,
- How Meilisearch Updates a Millions Vector Embeddings Database in Under a Minute,
- Meilisearch Indexes Embeddings 7x Faster with Binary Quantization.
Wouldn't it be great to show you how a single-threaded, memory-mapped key-value store can be more efficient than a hand-written memory-mapped solution? I faced issues while porting the Spotify disk-based Approximate Nearest Neighbors library to Rust and, more specifically, to LMDB. Those issues were primarily due to LMDB and memory safety. Here is the story.
To remind you, Arroy is a library that stores embeddings (vectors of floats) on disk. Some data structures are generated on top of those vectors, which look like trees governed by normals used to recursively split the vectors dataset into subdomains. But you can read more about this in part 1 of this series.
How does Annoy Generate the Tree Nodes?
Annoy, the Spotify library stores the nodes on disk, the item nodes (the ones containing the embeddings), and the other nodes that we will call tree nodes in this article. The advantage of doing this is double:
- The program's memory usage is low and optimized by the OS as all the nodes live in a memory-mapped file.
- The concept is simple: Access a node by using its ID. The library will find its offset on disk by using a simple multiplication.
However, there are downsides to doing that. All nodes: items with embeddings along with the tree nodes must have the same size, and If a user wants to identify its embedding using the ID 231, the library will increase the file size to the ID multiplied by the node size. For example, with a vector of 768 dimensions, storing a single item with the ID 231 will generate a file of more than 6.5 TiB.
In generating the final data structure, the tree nodes are all written to disk in the same file as the user item containing the embeddings. Those tree-building processes run in parallel, one running process by tree, and, therefore, requires a lot of synchronization when defining the newly created node ID and the memory area reserved for it, most importantly, when the memory-mapped file is too small to accept more nodes, only a single thread must grow the file, so a mutex is used on top of the mutable memory-map and around a node_id variable. One interesting property of tree generation is that the generation process only requires the original user item with embeddings.
The Challenges We Encountered when Porting it to LMDB
A fun fact is that it is the first time in a long time that I have written C++, and the first time I asked ChatGPT to code for me because I was not confident in doing C++ and feared falling into some segfault. I needed a small program to deserialize embeddings from stdin and give them to Annoy. The chatbot's code was mostly effective, but it omitted a critical empty vector check, which led to a segmentation fault...
The main obstacle to porting it to LMDB is that writing into this key-value store is single-threaded. It doesn't support concurrent write operations to maintain a correctly balanced BTree. Fun incoming!
Reading the User Item Nodes from Different Threads
We have used LMDB at Meilisearch since the beginning. It is a well-maintained key-value store used in Firefox and maintained by the OpenLDAP developers. It is memory-mapped and does not maintain a user-end cache of the entries in memory but instead gives you a pointer to the memory-mapped area on disk. The main advantage is that you can keep a pointer to this area for as long as your read transaction lives. Ho yeah! Because it is a transactional key-value store that supports atomic committing, too!
But tree generation doesn't require referring to the generated nodes but only the user items. We previously saw that LMDB gives direct pointers into the memory-mapped file without maintaining any intermediate cache (that could be invalidated). There is another quirk with LMDB: you cannot share a read-only transaction between multiple threads, i.e., RoTxn: !Sync and you cannot move the write transaction between threads, i.e., RwTxn: !Send + !Sync. Ho! And there is no way to create a read-transaction on uncommitted changes. This is an issue because we want to generate the data-structures trees in the same transaction where we store the items.
But magic is everywhere, starting with the following small and fun data structure. The principle is to keep the pointers to the internal user items with embeddings in a Vec<*const u8>. Thanks to Rust, we can ensure, at compile time, that the pointers will live long enough by keeping the lifetime in the struct. Using the &'t RwTxn to get the &'t RoTxn by using Deref also ensures that we cannot modify the database while reading in it by using a &'t mut RwTxn. According to the leading developer of LMDB, it is safe to share those pointers between threads and why I implemented Sync for this structure.
pub struct ImmutableItems<'t, D> {
item_ids: RoaringBitmap,
constant_length: Option<usize>,
offsets: Vec<*const u8>,
_marker: marker::PhantomData<(&'t (), D)>,
}
impl<'t, D: Distance> ImmutableItems<'t, D> {
pub fn new(rtxn: &'t RoTxn, database: Database<D>, index: u16) -> heed::Result<Self> {
let mut item_ids = RoaringBitmap::new();
let mut constant_length = None;
let mut offsets = Vec::new();
for result in database.items()? {
let (item_id, bytes) = result?;
assert_eq!(*constant_length.get_or_insert(bytes.len()), bytes.len());
item_ids.push(item_id);
offsets.push(bytes.as_ptr());
}
Ok(ImmutableItems { item_ids, constant_length, offsets, _marker: marker::PhantomData })
}
pub fn get(&self, item_id: ItemId) -> heed::Result<Option<Leaf<'t, D>>> {
let len = match self.constant_length {
Some(len) => len,
None => return Ok(None),
};
let ptr = match self.item_ids.rank(item_id).checked_sub(1).and_then(|offset| self.offsets.get(offset)) {
Some(ptr) => *ptr,
None => return Ok(None),
};
let bytes = unsafe { slice::from_raw_parts(ptr, len) };
ItemCodec::bytes_decode(bytes).map(Some)
}
}
unsafe impl<D> Sync for ImmutableItems<'_, D> {}You have also probably noticed some other fun optimizations in this simplified version of the data structure. We also know that the user-item nodes have a constant length, so I decided to store it only once, reducing the offsets vector's size by two. Considering that our objective is to store 100M vectors and that this vector is in memory, we shrunk its size from 1526 MiB to 763MiB, which is not much, but better than nothing.
Writing the Tree Nodes in Parallel
Ok! Now that we know how to store pointers to items and share them between threads without any user-end synchronization, we need to generate the tree nodes using it. We already know how to deal with LMDB at Meilisearch and decided to implement the same workaround. To write in parallel into LMDB, write into different, independent files and merge everything afterward. This leverages the Share-Nothing principle and isolates the algorithms. This drastically reduces the number of synchronization points compared to the original C++ code (look at the .lock/unlock calls) to a single line in our code: the atomically increasing global tree node ID.
pub fn next_node_id(&self) -> u64 {
self.0.fetch_add(1, Ordering::Relaxed)
}Our functions that generate normal split nodes based on the user-item nodes are now simply writing the nodes into independent files. The nodes are appended into a file, and the on-disk offsets and bounds are stored into a vector, a single usize by node. Using Rayon, we run all tree-generation functions in parallel and, once completed, retrieve the files and boundaries to write the uniquely identified nodes into LMDB sequentially.
Performances Comparison
Our objective at Meilisearch is to support 100M embedding of around 768 dimensions. If we store those as f32 vectors without any dimensionality reduction, it would be equivalent to 100M * 768 * 4 = 307B, in other words, 286 GiB to store the vectors raw, without any internal tree nodes, i.e., no way to search in them efficiently.
If you don't specify the number of trees to generate, the algorithm will continue to create trees while the number of tree nodes is smaller than the number of item vectors. At the end, there must be roughly the same number of tree nodes and items.
Discovering the Limit of Vectors We Can Index
Arroy and Annoy use memory mapping extensively but in slightly different ways. In a previous article from @dureuill, we saw that operating systems do not have infinite memory-map space. So, let's dive into performance results.
I noticed something strange when running Arroy with 25M vectors of 768 dimensions. The CPUs were not used, and the program seemed to read the SSD/NVMe a lot, too much 🤔 The tree generation algorithm is splitting the vector space into subdomains with fewer vectors. Still, it must first find the appropriate normal to split the entire domain, and for that, it randomly selects many items. Unfortunately, my machine only has 63 GiB of memory, and indexing those 25M items requires more than 72 Gib. Annoy was also struggling in the same way.
After investigating, I understood why the whole swap space and memory mapping limits were reached. The item nodes were not only 768 * 4 bytes because we store the norm and other stuff alongside the vectors, but in the case of Arroy, LMDB needs to maintain BTree data structures around the entries, and those are also tacking memory-mapped space. Both programs request random item nodes unavailable in memory, so the OS fetches them from the disk, which takes time. Ho and every single thread is doing that in parallel. CPUs are simply awaiting the disk.
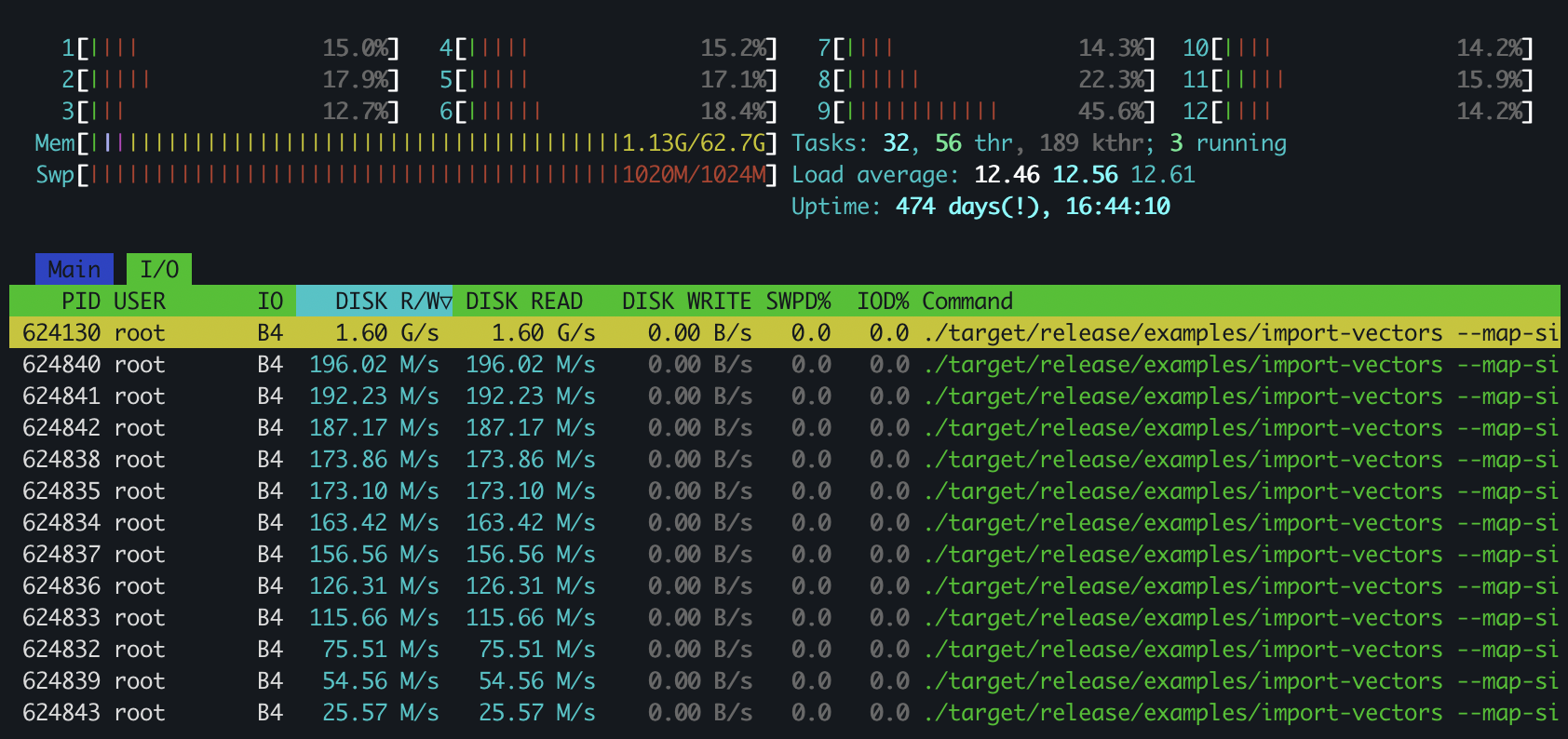
So, after some dichotomy, I found the point where arroy successfully used all of the memory without being bound to the disk speed. It can index 15.625M on a 63 GiB machine. You can see on this htop screenshot that the disk read speed is at zero as all of the vectors fit in RAM, that arroy is writing the tree nodes to disk, and that the CPUs are doing their best. It took less than seven hours to process.
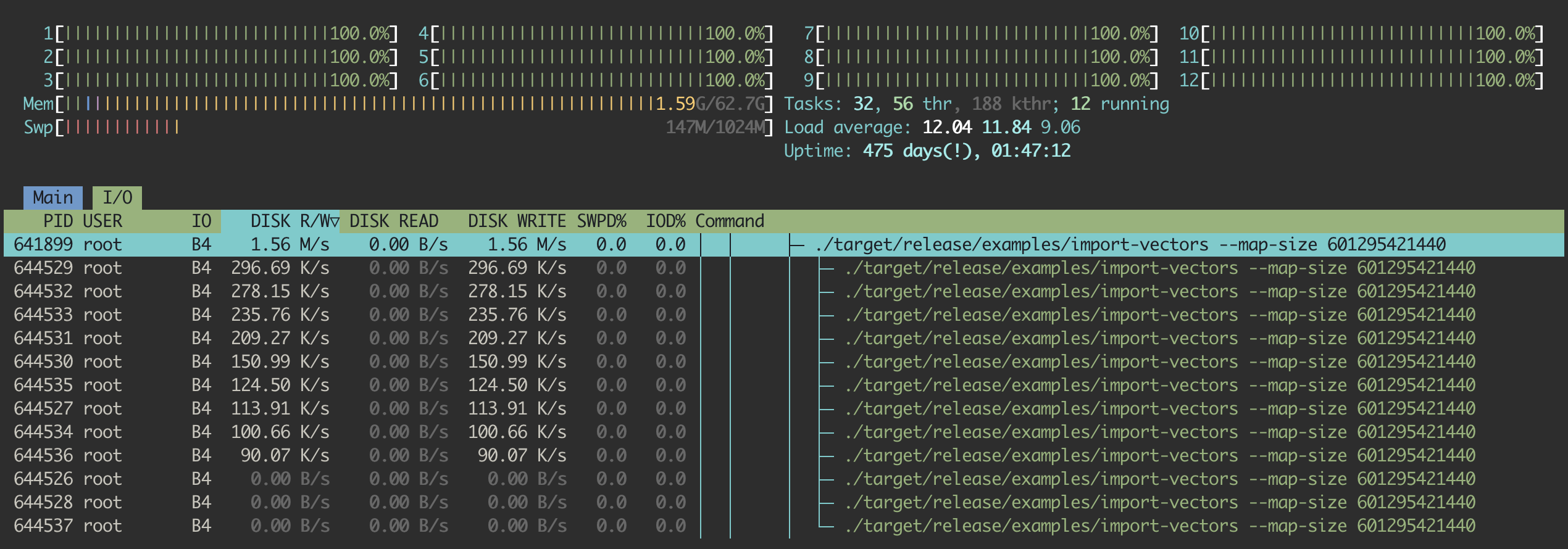
But... Annoy cannot index this same number of documents. It suffers from the same issue we saw before: high disk read and low CPU usage. But why? I needed clarification because the nodes have the same format, the number of item vectors to index is the same, and the algorithm has been ported. So, what is the difference between both solutions?
For those who looked into the C++ codebase and were probably hinted by the memory mapping issue described earlier, you probably noticed this slight difference: Arroy is writing the generated tree nodes into different raw files when Annoy, on the contrary, is reserving space into the memory-mapped file and directly writing into it. By doing this trick, the OS needs to keep much more space in the memory-mapped area and is forced to invalidate the item nodes from the cache to keep the just-written tree nodes hot in the cache, slowing down the system for no reason, as the tree nodes are not necessary for the algorithm.
So, after even more dichotomy to find the Annoy limits on a 63 GiB machine, I discovered that it could roughly index 10M vectors in five hours.
The Share Nothing Principle to the Win
So Arroy can index 36% more vectors on the same machine, but how long does it take? Wouldn't it be faster to write into the same file in parallel instead of copying all those tree nodes in a single-threaded way? It will be a much shorter paragraph as I only did some small tests, but Arroy is always faster!
| number of vectors | number of threads | building time | |
|---|---|---|---|
| Annoy | 96k | 1 | 5min 38s |
| arroy | 96k | 1 | 3min 45s |
| Annoy | 96k | 12 | 1min 9s |
| arroy | 96k | 12 | 54s |
| Annoy | 10M | 12 | 5h 40min |
| arroy | 10M | 12 | 4h 17min |
| Annoy | 15.625M | 12 | -- |
| arroy | 15.625M | 12 | 7h 22min |
Now, you probably tell me that I will need around 400GiB of memory to index 100M vectors, and you are probably right, but @irevoire will talk about incremental indexing in a future article. I did a linear regression for fun. With those 12 threads and the required memory, I predicted it would take one day, 22 hours, and 43 min 😬. Ho! As we also use this vector store in Meilisearch, we need to provide ways to filter this data structure at search time. This is the next article in this series.
You can comment about this article on Lobste.rs, Hacker News, the Rust Subreddit, or X (formerly Twitter).