
Meilisearch is too slow
Consider this post about the drawbacks and solutions for the Meilisearch document indexer. We'll start with the current situation, explore the techniques, and finally draft a powerful new document indexer.
I'm currently on vacation, but as the CTO and co-founder of Meilisearch, I can't help but think about ways to enhance our product, particularly the document indexer. Writing helps refine my ideas, so I'm excited to share my thought process between mountain hikes.
Meilisearch is the second most starred search engine on GitHub. It features a straightforward HTTP API, is built in Rust, and integrates a hybrid search system that combines keyword and semantic search for highly relevant results. We need to optimize the indexer to handle better large datasets, including hundreds of millions of documents.
What is a Document Indexing Engine?
Every search engine is built upon inverted indexes. Inverted indexes are factorized key-value stores where the key corresponds to an item appearing in a set, and the set is the bitmap linked to it; for example, a word -> docids inverted index matches words to a bitmap of document IDs that contain those words, such as chocolate, which appears in documents 1, 2, 20, and 42. Meilisearch uses around twenty-one different inverted indexes to deliver highly relevant search results. Additionally, it employs various interesting data structures, such as the arroy tree, to enhance its functionality.
The current indexing engine is highly efficient, capable of indexing 250 million documents in about twenty hours on a high-CPU machine. However, there is still room for significant improvement. This article will explore the recipe for building an even better indexer.
Arvid Kahl bought a 96-core machine, hoping Meilisearch would use them efficiently, but it didn't.
Internally, we've noticed a trend: customers want to index hundreds of millions of documents and update them frequently. One customer has over 311 million documents, growing by about ten million each week. The search engine is so fast and reliable with large datasets that users don't notice indexing issues until they need to reindex everything from scratch. This usually happens when loading Meilisearch dumps or bulk updates from SQL databases, especially during initial setup.
A Little Bit of History
We introduced diff-indexing less than a year ago. Before version 1.6, our engine struggled with updates and deletions. It used to soft-delete documents and index the new version as if it were entirely new, leading to increased disk usage, complexity, and bugs. This method required reindexing everything and acting like a garbage collector, deleting soft-deleted documents only when a certain threshold was reached, which impacted random updates.
Since version 1.6, the indexing pipeline has become much more efficient. It processes both the current and new versions of a document to determine only the necessary changes to the inverted indexes. This approach has drastically sped up document updates by reducing the number of operations in LMDB. The differential indexer uses extractors to create chunks, essentially inverted indexes of deletions and insertions applied to the bitmaps in LMDB.
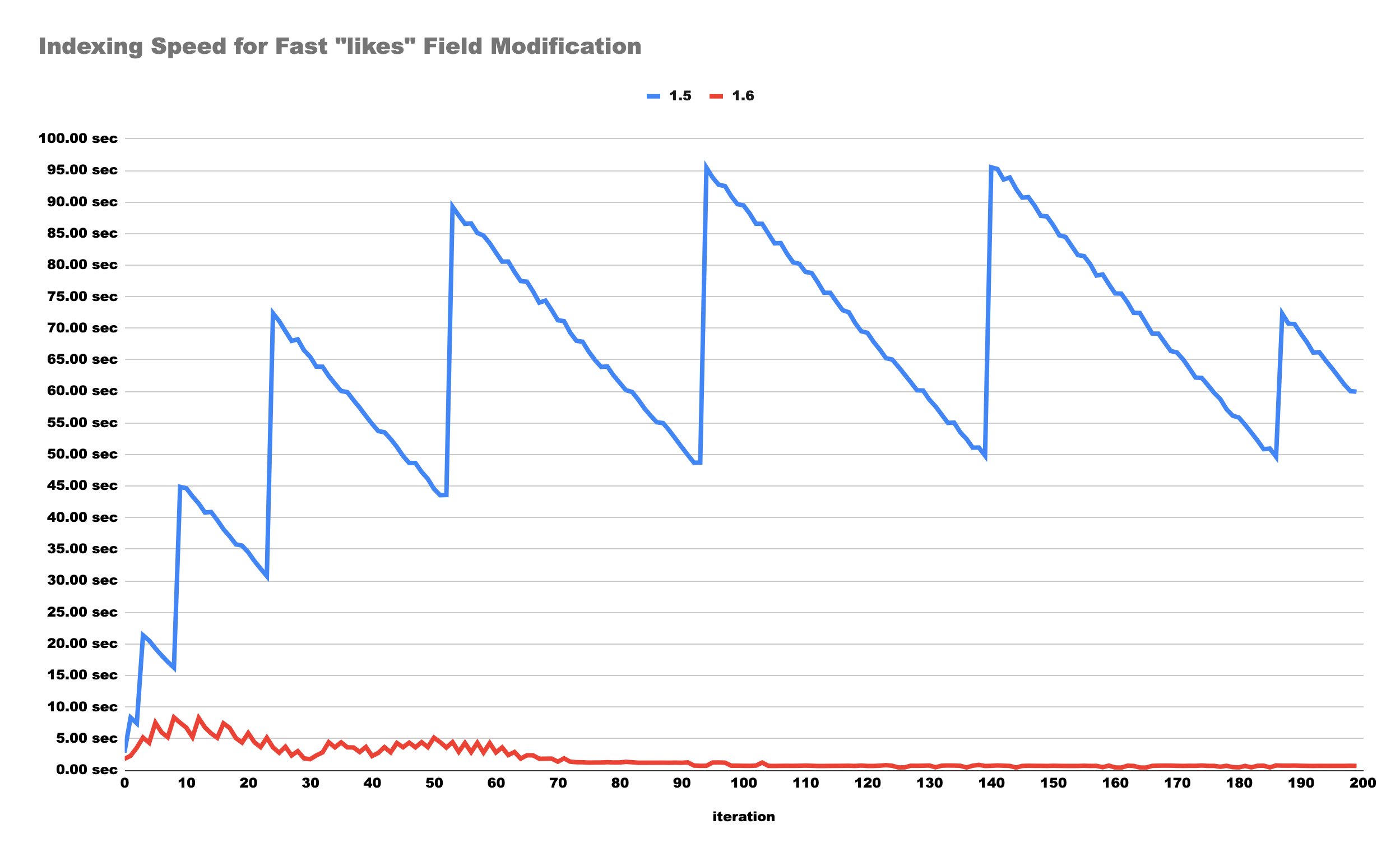
The blue spikes represent a 99% auto-batching and 1% garbage collection of soft-deleted documents no longer visible in v1.6.
LMDB, which stands for Lightning Memory-Mapped Database, is the core component of a Meilisearch index. It's a fantastic key-value store because it:
- Scales reads with the number of CPUs,
- Supports zero-allocation reads,
- Supports atomic and fully serialized transactions,
- Needs minimal configuration,
- Has a small API surface,
- Has low write amplification,
- Is reliable, having been used in Firefox for years.
But it has some downsides:
- Visible fragmentation,
- Only one write transaction at a time,
- Non-aligned value bytes, limiting zero-copy deserialization.
This article will explore the details of Howard Chu's amazing key-value store.
In 2022, we released the first version of our Cloud ✨ but experienced numerous out-of-memory crashes.
A Disk-Based Indexer to Fight OOM
We revamped the indexing system to be chunk-based, which drastically cut down on memory usage. Now, Meilisearch splits document updates into 4MiB temporary grenad files, processed by various extractors in parallel. Each extractor works on a chunk and produces one or multiple additional chunks, usually inverted indexes.
We designed our token extractors around grenad1 Sorters. The Sorter holds key-value pairs in an in-memory buffer until it's full. When full, it:
- Sorts the entries by key,
- Merges them by deserializing the Roaring Bitmaps,
- Performs bitmap unions,
- Serializes the unions,
- Writes the merged entries into a temporary file using a
Writer, - Once the limit of temporary files is reached, files are merged together.
This process includes:
- Sorting entries in O(n * log(n)),
- Multiple
memcpyoperations, - Numerous small allocations and I/O operations,
- Serializing bitmaps during insertion,
- Keeping the key multiple times in memory.
All of this requires significant resources, especially for high-frequency entries like chocolate in a recipe dataset or a science fiction tag in a movie dataset.
Most of the time, the extractors rely on other extractors, which in turn depend on the original document chunks. This dependency chain can lead to long-lived temporary grenad files, causing a buildup of open files and resulting in too many open files errors during indexing. Having many open files also puts extra pressure on the filesystem's cache, which can further degrade performance.
When extractors finish producing chunks, we send them directly to the LMDB writer. The writing thread's tasks include:
- Going through grenad file entries and decoding bitmaps for deletions and insertions,
- Retrieving and decoding the bitmap for each corresponding key in LMDB,
- Making deletions and insertions on the LMDB bitmap,
- Encoding and saving the updated bitmap back into LMDB.
// For each inverted index chunk received
for chunk_reader in chunks_channel {
// Iterate throught the grenad file entries
let mut iter = chunk_reader.into_cursor();
while let Some((key, deladd_bitmaps)) = iter.next()? {
// Deserialiaze both operations
let deletions = deladd_bitmaps.get(Deletion).unwrap_or_default();
let additions = deladd_bitmaps.get(Addition).unwrap_or_default();
// Get the bitmaps from LMDB and do the operations
let mut bitmap = database.get(wtxn, key)?.unwrap_or_default();
bitmap -= deletions;
bitmap |= additions;
// Serialize and write back into LMDB
database.put(wtxn, key, &bitmap)?;
}
}Meilisearch can't perform merging in parallel because the operations depend on chunks that have already been merged within the ongoing write transaction. In simpler terms, we've made changes within the current transaction that aren't yet visible to read transactions. This means we can't open multiple read transactions to work in parallel.
LMDB's read-your-write feature allows us to see what we've just written in the write transaction. However, frequent writes to the same entries can lead to increased database fragmentation and memory usage, as LMDB keeps hot pages in a malloced area to reduce disk writes. As a result, we often notice that only a single working thread is active when inspecting slow indexations.
The Meilisearch task scheduler auto-batches tasks to improve latency and indexing speed for large datasets. However, it's not optimized for real-time indexing due to varying task sizes. Initially, auto-batching was introduced to handle users sending documents one by one, which slowed down indexing. Sometimes, Meilisearch processes too many tasks and crashes (OOM killed). This could be fixed by designing the auto-batching system around the total batch size instead of the task count.
In conclusion, while we have successfully addressed out-of-memory issues, we now face higher disk usage and increased filesystem pressure. Disk operations are slower than RAM access, and the available RAM is often only partially utilized. Additionally, the system frequently runs single-threaded, which impacts indexing performance.
A Better Indexing Engine
Rewriting is often considered taboo in our industry. The main reason is that rewriting a functionality delays new features and leads the project through uncertain delays and new bugs without providing immediate visible value. However, at Meilisearch, we embrace this principle because we have had great success with past rewrites and know how to manage them effectively.
The first example that comes to mind is the index-scheduler rewrite. We adopted a very sane methodology, where we listed the features we wanted for the release, those for the future, and the major bugs from the past year. By mixing these elements during two to four-hour peer coding sessions, we created an excellent product, free of significant bugs, with ideally shared knowledge that improved support, efficient bug fixing, and smooth feature addition.
Another example is the recent Spotify/Annoy port, from C++ to Rust on top of LMDB. A series of blog posts details this story, resulting in a perfectly integrated library with shared knowledge, better performance, and fewer bugs.
When a software component is built from the ground up with each required feature in mind, it becomes significantly better designed, typed, understandable, and future-proof. This contrasts with components initially intended to accommodate only some planned features and, therefore, struggle to integrate necessary changes.

Available Tricks and Techniques
Let me highlight some of the tricks and techniques we've learned with LMDB, which will be essential for the new document indexer we want to implement. The current indexer can't efficiently use these techniques; attempting to do so would add complexity and lead to more bugs.
LMDB only allows a single write transaction at a time, which is the key to its serializability, whereas RocksDB supports multiple parallel writers. This fundamental difference had previously limited my thoughts on how Meilisearch could be optimized. However, we've realized that reading in parallel while writing is possible with LMDB. This is the most impactful discovery for enhancing the Meilisearch indexer! We can access the database content while using the write transaction by using a read transaction in each indexing thread — note that having more readers while writing clearly impacts write throughput. However, LMDB, with a single writer, remains impressively performant compared to RocksDB, with large values that we tend to have, i.e., large bitmaps. Additionally, LSM trees have higher write amplification, especially when writing in parallel, which we aim to minimize.
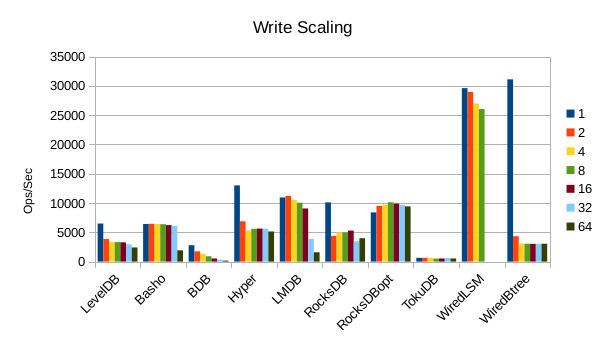

LSMs excel at handling small, write-heavy tasks, whereas LMDB performs better with larger values. Graphs above show the performance for inserting and reading 4k values.
The Meilisearch indexer determines the operations to execute on the database. These operations are represented by specifying document IDs to remove from and insert in given bitmaps in LMDB. The ability to read the database in parallel while writing to it opens up the possibility of performing these merge operations in parallel and sending the final serialized bitmaps to the main writing thread, further balancing the computational load.
However, this optimization only works if we stop reordering settings updates with document updates and handle them in a single write transaction. The current engine tries to be smart by processing settings first, which can reduce work for new documents. However, handling everything in one transaction can trigger MDB_TXN_FULL errors because the transaction gets too big. These settings changes are rare, and optimizing this way makes it impossible to read the inverted indexes due to intermediate settings changes.
When implementing the multi-threading support of arroy, we found a way to read uncommitted changes in parallel from LMDB. For detailed insights and code examples, check out my vector store implementation writeup. This technique leverages LMDB's read-your-writes capability and the zero-copy memory-mapping principle: Entries in LMDB are pointers to the memory-mapped area, valid until the environment is dropped or any further writes occur. Gather the pointers to the desired entries, then share them in parallel while ensuring the write transaction remains untouched.
We plan to execute a single write to set the state of the entries by first preparing the final inverted index bitmaps as described above. Once these operations are merged in parallel, the result will be sent to the writing thread. Constructing a disk-based BTree can be allocation-intensive, but LMDB offers the MDB_APPEND parameter, which allows entries to be appended to the end of a database if they are still in lexicographic order. This reduces the overhead of the insertion process, reduces fragmentation, and decreases write amplification.
We can further enhance performance by reducing communication overhead and data transfer between threads. The most effective strategy is to serialize the bitmaps into an in-memory buffer, ideally in parallel. This allows for minimal allocations and uses wait-free data structures. When combined with a hot reading loop on the writing thread end, the bbqueue crate is a promising solution.

Illustration from the bbqueue blog post by ferrous systems, demonstrating the method of reading in a circular buffer.
One of the earlier versions of grenad2 included a feature that enabled file streaming while deallocating read parts, thus freeing space for the database or other grenad files. This feature could help reduce write-amplification using the fallocate(2) system call, currently available only on Linux. This feature is handy when the grenad Sorter needs to merge temporary files.
The Set of Features to Support
Now that we've explored all these exciting new tools and techniques, let's see how we can use them to make our document indexer faster and more efficient, while also supporting the cool new features we have in mind.
People mainly use Meilisearch for document insertion, either by merging (PATCH) or replacing (POST) documents. Users send their documents through HTTP routes, and Meilisearch accepts them asynchronously, converts them into grenad JSON files and registers them in the index scheduler. To accommodate users who send documents one by one, the scheduler auto-batches multiple tasks to be processed in a single transaction. The indexer then deduplicates and writes the final document versions into another temporary grenad file. This method led to data duplication and slower performance on slow disks. I tried merging documents on the fly and using a parallel iterator with the new multithreaded indexing pipeline, and the results have been fantastic.
Another common task is upgrading to the latest Meilisearch version. This involves creating and loading a dump with the new engine. A dump is a tarball (.tar.gz) containing index settings and documents in a JSON-lines file. The order of files in the tarball matters because you can only access them sequentially. To prepare indexes efficiently, we need to reorder files so that settings come before the large document files.
When loading dumps with hundreds of millions of documents, we often hit the MDB_TXN_FULL error because the transaction gets too big. This happens due to many writes and overwrites during the processing and merging of grenad chunks. To fix this, we can process the documents in smaller chunks across different transactions, and since the database is empty when loading a dump, using the MDB_APPEND option helps add entries and cut down on dirty pages.
Settings often change during an index's lifespan. We have recently invested a lot of effort into differential indexing and plan to maintain this approach. We only provide the necessary document fields (e.g., newly declared searchable/filterable fields) to the extractors. Since the documents themselves do not change, we can skip the document writing loop, avoiding some disk operations.
We recently launched the "edit documents by function" feature, which lets users reshape documents by modifying any attribute through a custom function. Currently, this function is applied to all documents in parallel, resulting in a single grenad JSON file before continuing with the standard indexing process. This can cause space issues when editing many documents. Instead of writing everything to disk, we should stream the newly edited documents. By doing this, even if we run the function multiple times, we can generate the different inverted indexes and write them into LMDB.
Analyzing our largest customers' databases, we found that the documents database, where we store raw JSON for optimal retrieval, is the biggest. We started using zstd for dictionary compression by sampling 10k documents to create a dictionary, which reduced size by 2-3 times. The current indexer compresses documents after indexing, slowing things down, so we didn't merge the PR. The new indexer will hold enough documents in memory to build the compression dictionary, enabling compression and parallel streaming of documents during the indexation.
We want to cut down on disk usage to make better use of CPUs and memory, avoiding slow I/O waits. We noticed that grenad Sorters weren't using available memory efficiently, relying too much on disk writes. To fix this, we'll add a cache for each indexing thread to handle entries in memory first, writing to disk only when necessary. We'll also ensure these caches don't use too much memory to prevent OOM issues. We could even tweak the roaring and lru crates to support custom allocators, just like hashbrown supports bumpalo, thanks to the Allocator trait.
The current engine uses 4MiB document chunks, which are then processed by extractors to generate new chunks for the writing thread or other extractors. This method can be inefficient because if one chunk is more complex to process, it can slow down the entire pipeline. Instead, we can use Rayon and its work-stealing feature to process documents individually. This way, if some documents are harder to process, the workload is balanced more efficiently across threads.
One of Meilisearch's key tools is charabia, which handles language detection through Whatlang and efficient token extraction and normalization. We're considering switching from the Whatlang library to Whichlang for a 10x speed boost. We're also working on making charabia faster, with the help of @ManyTheFish, to speed up the entire extraction process.
To support different types of indexing — realtime and large insertions — we can tweak the task scheduler to batch tasks based on the size of the document payloads sent by users. Larger batches mean longer latency but faster overall indexing. Smaller batches allow quicker visibility of documents but take longer to index all tasks. By configuring the auto-batch size, users can choose their preferred behavior.
Future Improvements
We aim to make Meilisearch updates seamless. Our vision includes avoiding dumps for non-major updates and reserving them only for significant version changes. We will implement a system to version internal databases and structures. With this, Meilisearch can read and convert older database versions to the latest format on the fly. This transition will make the whole engine resource-based, and @dureuill is driving this initiative.
To determine the best way to handle the inverted index content, we should measure disk speed. This will help us decide whether to write the content to disk for the LMDB writing thread to handle later or process the values in parallel and send them directly to the writing thread without using the disk. We will always compute the merged version of the inverted index in parallel with multiple read transactions.
Waiting can be challenging, especially without updates. By displaying the progress of indexing pipelines through multiple loading bars, we can make the wait more tolerable, keep users informed, and even assist in debugging slow pipelines for further improvements.
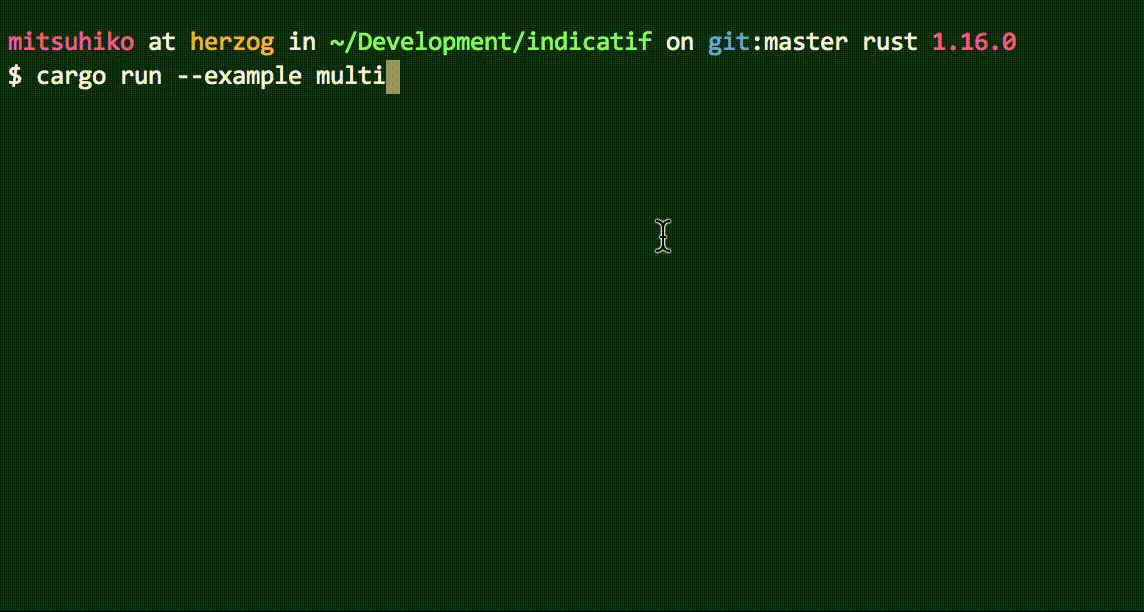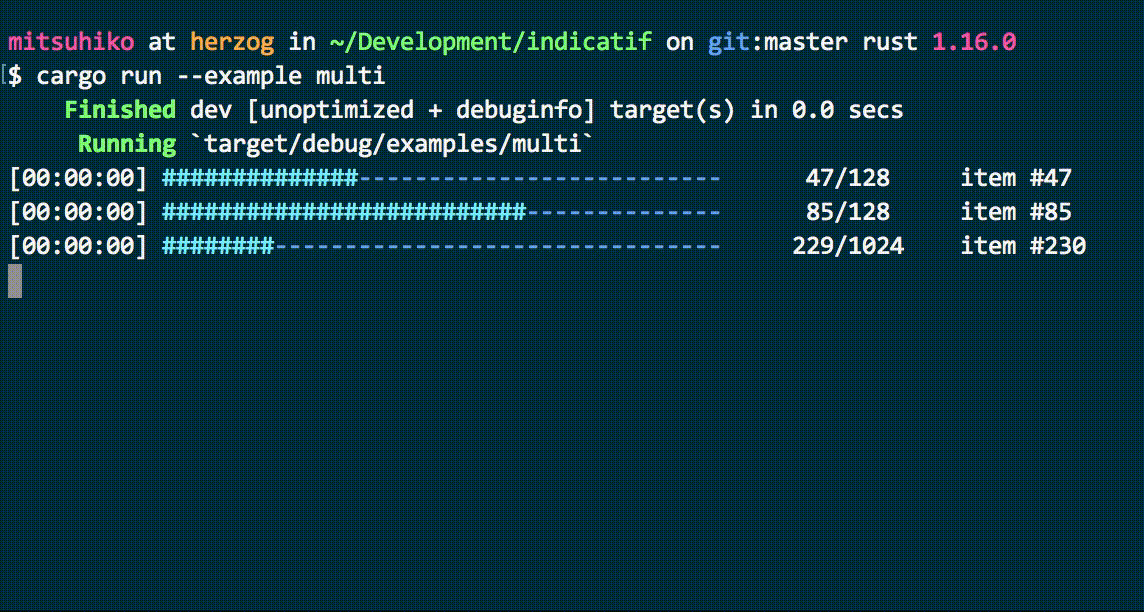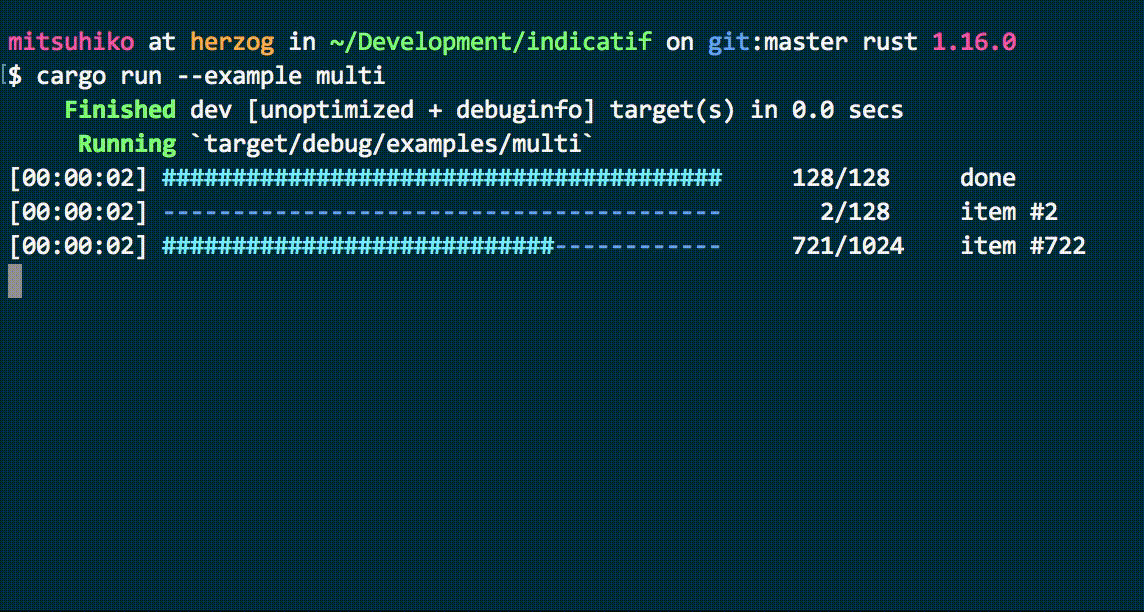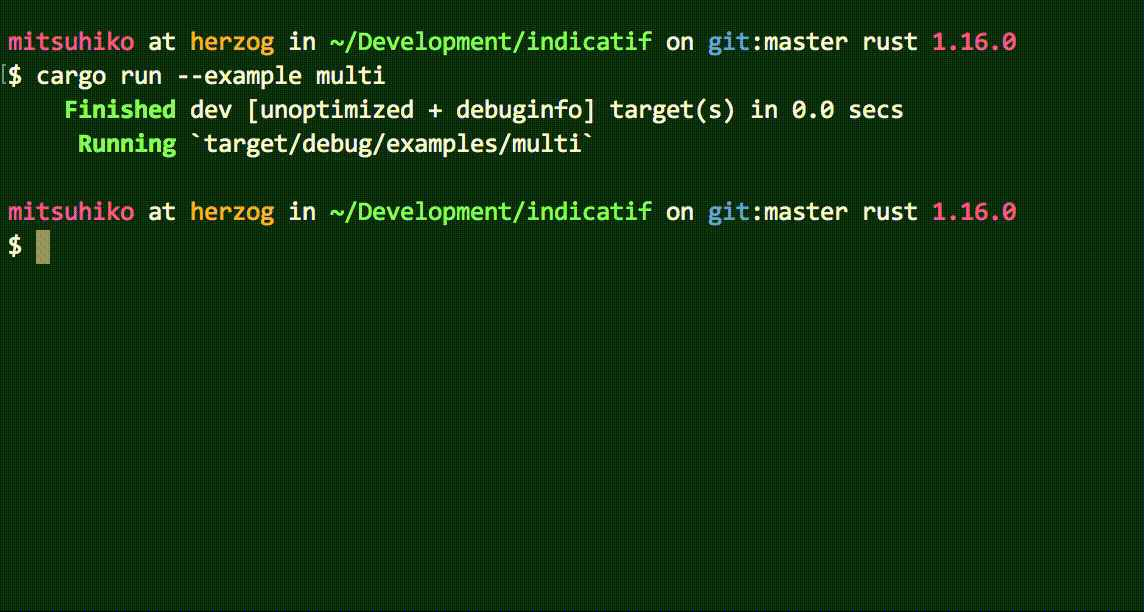
Cool loading bars from the console-rs/indicatif library. Imagine how awesome they would look on a web dashboard!
Wrapping Up
We aim to create a super-efficient key-value store, similar to an LSM, optimized for parallel writes to build the inverted indexes before updating the LMDB inverted indexes. By making smarter use of RAM to cut down on disk writes and gathering operations for LMDB, we can significantly reduce the number of writes into this B+Tree key-value store, primarily designed for heavy read operations. The good news is that we can compute these inverted indexes while writing into LMDB, making the process much more efficient.
I hope you found this exploration of techniques and improvements as exciting as we do! We're eager to implement these strategies in our indexer rewrite and thoroughly benchmark it across various machines and datasets. We aim to ensure minimal regressions and achieve significant speed-ups, especially on larger machines with extensive datasets.
If you have any questions or suggestions, feel free to comment directly on this post, HackerNews, Lobsters, the Rust sub-Reddit, or X (formerly Twitter). Stay tuned for more updates, and happy searching!
Footnotes
-
Grenad is a collection of immutable key-value store components I designed, drawing significant inspiration from LevelDB/RocksDB SST files. It includes a
Writerthat manages lexicographically-ordered entries and creates aReader, aReaderthat retrieves or iterates over these entries, aMergerthat streams sorted merged entries using multipleReaders, and aSorterthat temporarily stores unordered entries in a buffer before dumping them into aWriterwhen full. ↩ -
Here is the
grenad::FileFuseimplementation for reference. ↩