
Meilisearch vs Qdrant: Tradeoffs, Strengths and Weaknesses
Warning
I made a mistake using Qdrant; it's not slow when set up correctly. I noted that Qdrant allows searching and filtering without proper parameters, which can lead to misuse. Slowness can arise from a misconfigured index or if filterable attributes aren't listed. You can find the actual results in this comment. It's still interesting to notice that Meilisearch is more relevant when constrained than when searching the whole dataset.
Meilisearch is a highly performant, ultra-relevant search engine, and this article will help you better understand the latter adjective. The engine uses an internal library called arroy (made by Meilisearch) to organize and perform approximate nearest neighbor searches (ANNs). Meilisearch also supports a hybrid search feature, absolutely not based on fusion ranking (thank God!), which brings search results that are always relevant whether the query is keyword-based or requires semantic understanding.
To measure the performance of our random projections-based vector store, we compared it to the well-known Qdrant engine. We measured the indexing time, recall, cumulated search time, and disk usage on different datasets. You can review and run everything on our benchmarks GitHub repository.
Recall refers to the proportion of relevant documents retrieved from a search that are considered ideal based on the targeted query and the closest documents surrounding it. Recall@100 indicates that we have identified the top 100 documents before executing the search on Qdrant and Meilisearch, and we will count the number of documents they return from this perfect set. A higher recall score is better, with 1.00 representing a perfect recall.
Show Raw Benchmark data and more details
In this benchmark, we measure a cumulated search time by running a hundred random searches on the same dataset in different subsets of the large, one million document dataset. That's why the search time seems large—it's not a single search but a hundred. In the tables below, I divided the cumulated searches by the number of performed searches (100) to get the average search time.
The following screenshot compares an angular distance with a cosine one. Those two names refer to the same distance function. We recently changed "angular" to "cosine" on Meilisearch to align with our competitors and reduce confusion. You probably also noticed the arroy name. It's the name of the internal vector store engine we built for Meilisearch.
Finally, Qdrant exposes an "exact" parameter for the search that can return perfect results, but the downside is that it is very slow, too slow for normal end-user search usage. That's why we decided not to show it on our benchmarks. The goal of this parameter seems to be debug-oriented and not used in production.
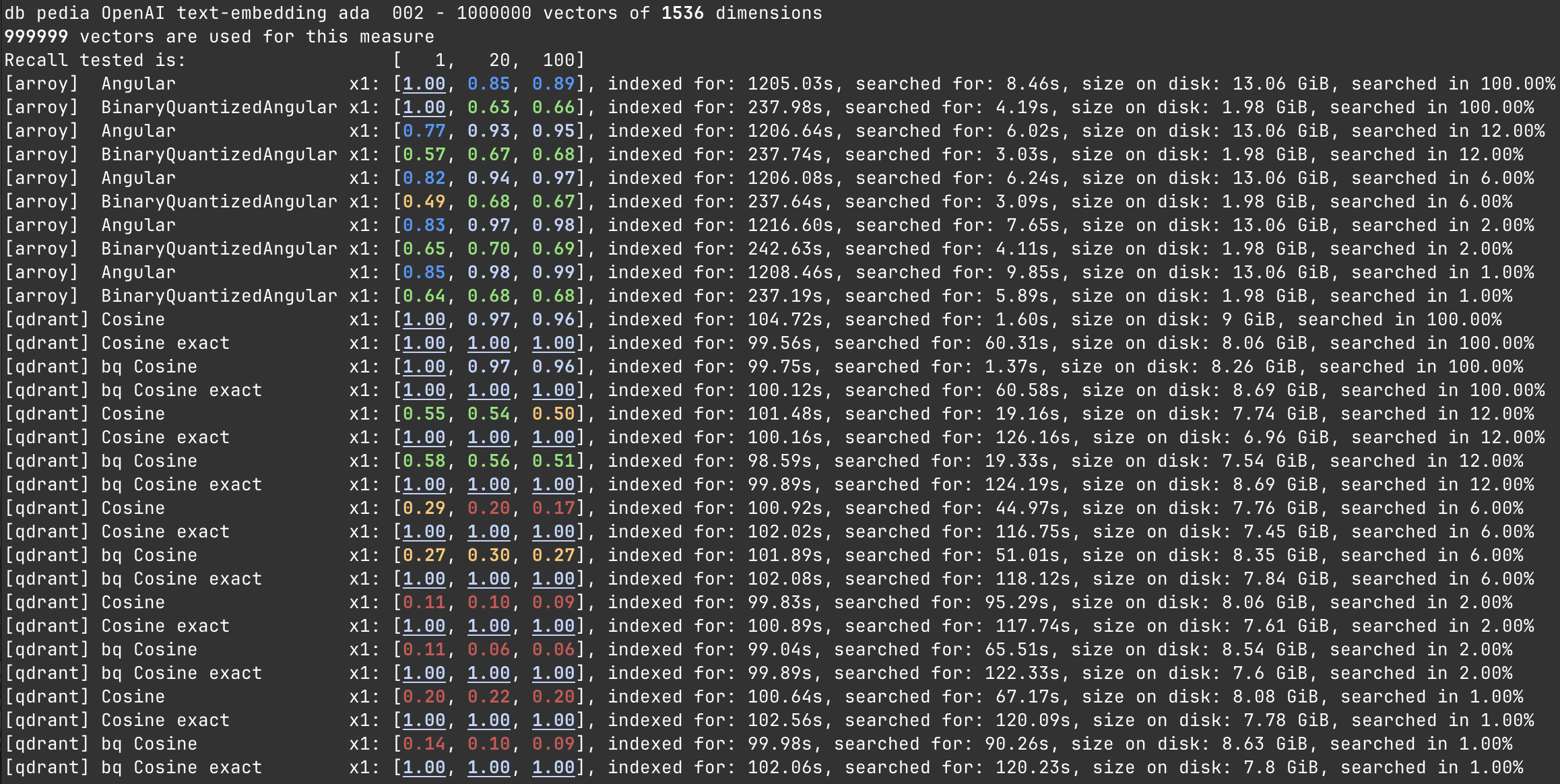
Searching in 100% of the Dataset
As we can see in the following table, Qdrant is more efficient than Meilisearch at indexing and searching the one million OpenAI (1536 dims) embeddings. However, enabling the binary quantization on both contenders shows a highly reduced disk usage on the Meilisearch side but also has the downside of highly reducing the relevancy.
| Version | Recall @1 | Recall @20 | Recall @100 | Indexing time | Average Search time | On disk size |
|---|---|---|---|---|---|---|
| Meilisearch | 1.00 | 0.85 | 0.89 | 1205s | 84ms | 13 GiB |
| Meilisearch Binary Quantized | 1.00 | 0.63 | 0.66 | 237s | 40ms | 2 GiB |
| Qdrant | 1.00 | 0.97 | 0.96 | 104s | 16ms | 9 GiB |
| Qdrant Binary Quantized | 1.00 | 0.97 | 0.96 | 99s | 13ms | 8 GiB |
Searching in 12% of the Dataset
This part of the benchmarks is where the results become interesting. We decided to filter the one million vectors we were searching on to only search in a subset of 12%, equivalent to searching 120,000 documents. We can see that Meilisearch is more relevant and faster than its competitor. Even when comparing the binary quantized versions, Qdrant shows weaknesses in this use case.
Qdrant still uses more than half of the disk space Meilisearch uses. However, searching this document subset becomes 3x to 6x slower than Meilisearch. Interestingly, the more you constrain Meilisearch, the better it gets in relevancy and search time.
| Version | Recall @1 | Recall @20 | Recall @100 | Indexing time | Average Search time | On disk size |
|---|---|---|---|---|---|---|
| Meilisearch | 0.77 | 0.93 | 0.95 | 1206s | 60ms | 13 GiB |
| Meilisearch Binary Quantized | 0.57 | 0.67 | 0.68 | 237s | 30ms | 2 GiB |
| Qdrant | 0.55 | 0.54 | 0.50 | 101s | 190ms | 8 GiB |
| Qdrant Binary Quantized | 0.58 | 0.56 | 0.51 | 99s | 190ms | 8 GiB |
Searching in 6% of the Dataset
We tried to reduce the subset further to see if Qdrant uses a different algorithm when the subset of documents is even smaller. We benchmarked by searching in a 60,000 vector subset this time.
As you may see, Qdrant relevancy is even worth than when searching in 12% of the dataset. This time, even the binary quantized version of Meilisearch is between 6 and 36 points more relevant than the non-quantized Qdrant version. It indeed seems that the engine doesn't switch algorithms when the subset becomes very small. On the other hand, Meilisearch became even more relevant. As spotted before, the engine is more relevant and up to 17x faster when the use case is to search in a very constrained subset of documents.
| Version | Recall @1 | Recall @20 | Recall @100 | Indexing time | Average Search time | On disk size |
|---|---|---|---|---|---|---|
| Meilisearch | 0.82 | 0.94 | 0.97 | 1206s | 60ms | 13 GiB |
| Meilisearch Binary Quantized | 0.49 | 0.68 | 0.67 | 238s | 30ms | 2 GiB |
| Qdrant | 0.29 | 0.20 | 0.17 | 101s | 450ms | 8 GiB |
| Qdrant Binary Quantized | 0.27 | 0.30 | 0.27 | 102s | 510ms | 8 GiB |
Searching in 1% of the Dataset
For the sport, we further reduced the subset to see how well Meilisearch was performing, and we indeed noticed nearly perfect relevancy results when using the non-quantized version. However, Qdrant struggles to reach 22% recall in about 10x longer than Meilisearch.
As you can see, the Meilisearch binary quantized version is good enough and clearly better than any Qdrant version. So, if you have disk size constraints and want to reduce the indexing time by six while still being more than three times more relevant than Qdrant, you can still use this solution.
| Version | Recall @1 | Recall @20 | Recall @100 | Indexing time | Average Search time | On disk size |
|---|---|---|---|---|---|---|
| Meilisearch | 0.85 | 0.98 | 0.99 | 1208s | 100ms | 13 GiB |
| Meilisearch Binary Quantized | 0.64 | 0.68 | 0.68 | 237s | 60ms | 2 GiB |
| Qdrant | 0.20 | 0.22 | 0.20 | 100s | 670ms | 8 GiB |
| Qdrant Binary Quantized | 0.14 | 0.10 | 0.09 | 102s | 900ms | 8 GiB |
What we Learned?
Meilisearch doesn't use an HNSW or a DiskANN for its performant vector store. Instead, it uses a random projections approach to split the dataset into multiple random trees and store everything in LMDB. After our filtering system extracted the subset of documents to search for, we dive through the tree nodes and filter the documents along the way. Computing so many nodes takes a long time to index but unlocks a snappy search service with high relevancy and recall. Everything is a matter of tradeoffs in computer science.
Still, as it is too slow, we plan to investigate and improve the indexing time. We will perform tweaking, like reducing the number of trees and tree nodes, and review how it affects relevancy, obviously.
On the other hand, Qdrant uses a RocksDB-backed HNSW with an in-house filtering system. It takes 10x less time to index the documents but still uses considerable space. Unfortunately, this algorithm is inefficient when the amount of data is large enough and the subset is small. We also benched with 100k documents, and Qdrant performed well. But at Meilisearch, it is more common to see customers with more than a million documents than the contrary.
What are the Use Cases?
Meilisearch is ideal for multi-tenancy systems where multiple users' data is merged into a single index. For instance, in a Bluesky-like app, all posts can be stored together, allowing users to search for relevant content from the last month or specific hashtags.
Similarly, in an eCommerce or marketplace platform, products are stored in one index with details like price, category, description, and shipping region. Users typically filter by price or category first and then perform a semantic search, significantly reducing the data set for approximate nearest neighbors (ANNs) on which Meilisearch performs better.
Furthermore, Meilisearch is designed for direct use by end-users from the front end of any application or eCommerce website. The search must be as snappy and quick as possible, without latency. However, when doing a semantic search, the embedding must be generated by a third-party API, e.g., OpenAI or Anthropic, which already brings a lot of latency. As you have seen, Meilisearch pulls down the latency as much as possible when Qdrant shows latency, just for the local ANN search, which is as high as a second.
Now that you understand Meilisearch's capabilities and the internal vector store, Arroy, I hope you will create something amazing with this wonderful open-source software. 🚀